The Power of Multi-Language eDiscovery Review in a Unified Platform

Share
Litigation no longer stops at language borders. Today, a single corporate investigation can surface emails in Mandarin, contracts in German, chat logs in Arabic, and spreadsheets in Portuguese, all demanding review at the same speed and to the same legal standard as English-language documents. For legal teams without the right infrastructure, this is where multi-language document processing solutions become a make-or-break capability.
The stakes have never been higher. The global eDiscovery market is on track to reach USD 32.5 billion by 2032, driven largely by the explosion of cross-border litigation, increasingly aggressive international regulators, and a data environment where a single enterprise generates information in dozens of languages simultaneously.

Yet most legal teams are still solving this problem the hard way: one tool for English-language review, a third-party translation vendor for foreign documents, manual handoffs between systems, and a chain of custody that stretches and sometimes breaks across every step.
What follows is a clear-eyed look at why multilingual eDiscovery demands a fundamentally different approach, what a truly unified platform can do that fragmented tooling cannot, and how Venio Systems delivers that capability in a single, defensible workflow.
Why Multilingual eDiscovery Is No Longer a Niche Problem
There was a time when multilingual documentation in litigation was the domain of multinational firms handling foreign sovereign investigations. That time has passed.
Today, cross-border disputes are mainstream. In fact, an overwhelming 87% of respondents now choose international arbitration to resolve cross-border disputes, either as a standalone mechanism (39%) or alongside Alternative Dispute Resolution (48%).
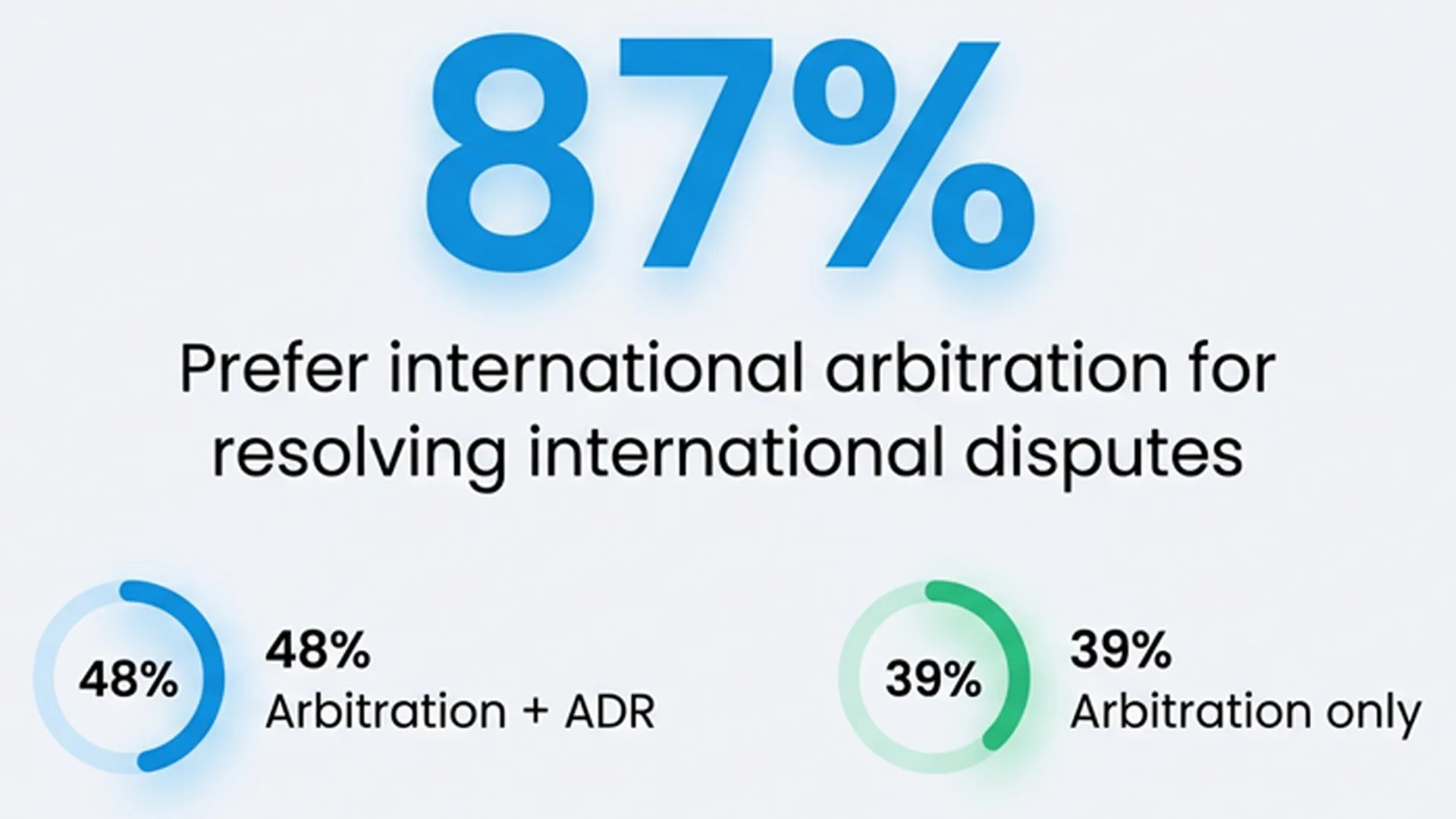
International markets are steadily expanding their share of the eDiscovery landscape, driven by new privacy regulations, complex multinational investigations, and broader adoption of digital discovery tools across jurisdictions that were previously underserved.
The data problem compounds this shift. Every multinational business generates ESI in multiple languages every day: customer communications, internal collaboration tools, financial records, and contract repositories that rarely respect the language boundaries of any given legal team.
The challenge is not just volume. It’s diversity. A corpus of 500,000 documents in a cross-border matter might contain primary content in three languages, metadata in a fourth, and embedded attachments switching between all of them.
For legal teams, this is not an abstract future-state problem. It is a live operational challenge in active matters right now, and the solutions many teams are using were not built for it.
Compare the Top eDiscovery Platforms for Global Matters
Discover the top 10 ediscovery vendors in the market and assess which one truly aligns with your needs.
The Hidden Costs of Fragmented Multi-Language Review
When legal teams lack a unified, language-aware eDiscovery platform, they compensate with workarounds. Those workarounds increase the cost of ediscovery. We call this the Platform Fragmentation Tax, the invisible premium paid in time, money, and legal defensibility when multi-language document processing services are stitched together from separate tools and vendors.
Cost #1: The Language Detection Problem
Identifying that a document is in a foreign language sounds simple. In practice, it is one of the most consequential steps in the discovery workflow. When scanned documents are processed through optical character recognition (OCR) without a language-aware configuration, the OCR engine defaults to the wrong character set.
Russian processed as English becomes gibberish. Arabic content processed without right-to-left character recognition is unreadable. Chinese ideographs are systematically miscaptured.
The result: potentially critical documents become non-searchable and effectively invisible to reviewers. They are not excluded from production because they were identified as non-responsive, or they are missed entirely because the platform never rendered them legible. This is not a minor efficiency issue. It is a defensibility risk.
Cost #2: The Translation Handoff Problem
For teams without integrated eDiscovery translation capabilities, the workflow typically looks like this: identify a document as foreign-language, export it outside the review platform, route it to a third-party translator, wait for the return, re-import, and then review. In high-volume matters, this cycle can take days per batch.
Beyond turnaround time, every handoff creates a chain-of-custody gap. When documents leave the secure review environment to travel through external translation services, they are exposed to data security and data privacy risks that can implicate cross-border privacy laws. In regulated industries such as finance, healthcare, and government, this is not a theoretical concern.
Cost #3: The Bilingual Attorney Cost
When technology fails to close the multilingual gap, legal teams fall back on human expertise. Bilingual attorneys command a significant premium over standard document reviewers, and as noted in industry research, this is the single most expensive element of the discovery phase in cross-border litigation.
On the other hand, AI, when properly deployed, can handle three times the review volume of a human reviewer. Without language-aware AI, that advantage disappears for any document not in English, forcing teams to staff expensively or accept delayed timelines.
What True Multi-Language Document Processing Looks Like in a Unified Platform
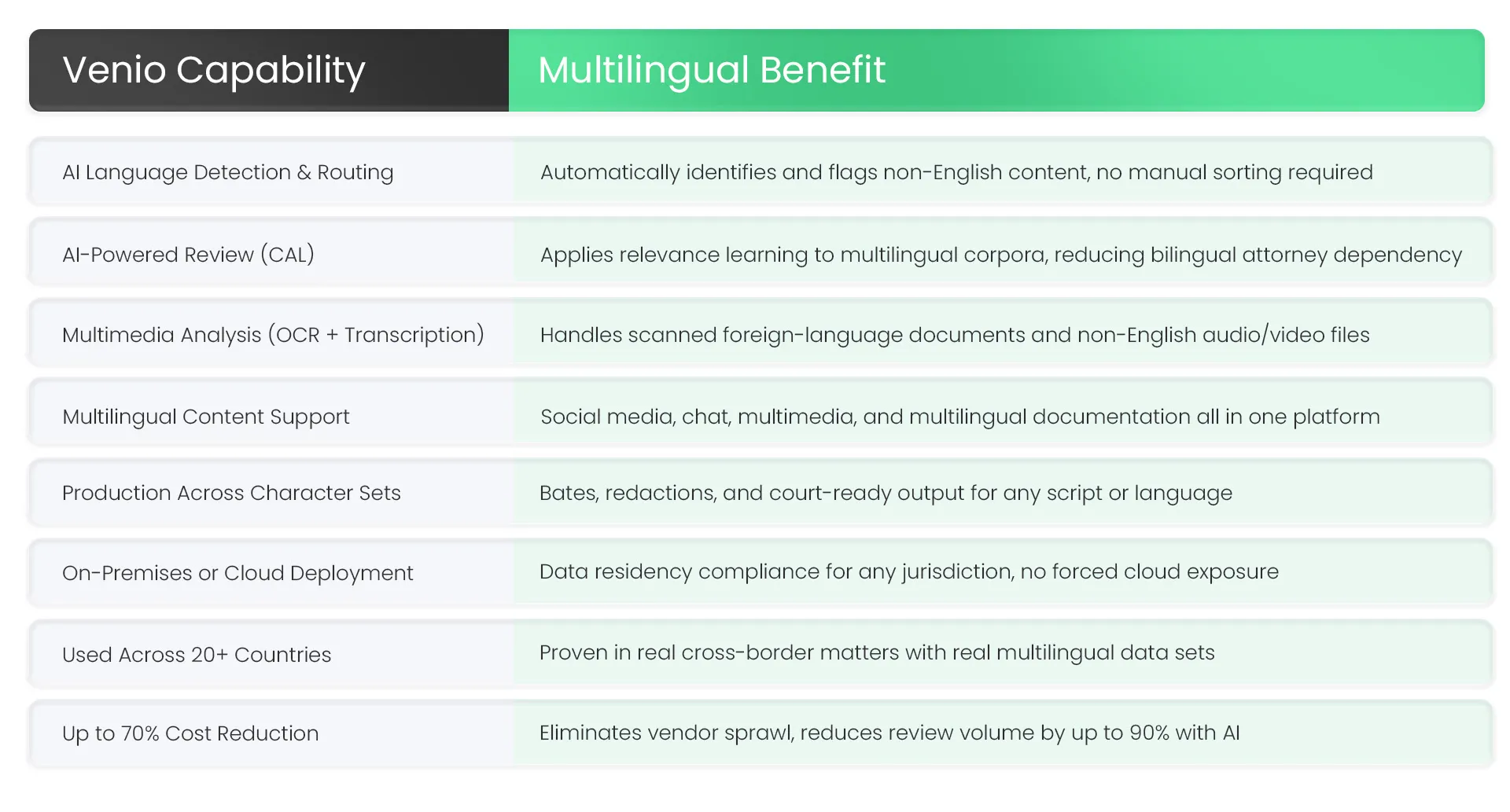
Not all eDiscovery platforms are built the same. There is a meaningful difference between a platform that handles multilingual content and one that is architected for it. Venio Systems falls firmly in the second category, i.e., built from the ground up to support multilingual documentation, social media, chat, multimedia, and complex ESI types within a single unified review environment.
Here is what that looks like in practice across the key stages of a multilingual matter:
Automatic Language Detection and AI-Assisted Multilingual Review
Venio’s AI engine automatically detects the language of documents and flags or routes non-English content for appropriate review or translation, a capability described by Venio as ‘critical for global matters or multilingual data sets.’ This is not a bolt-on feature. It is embedded in the same AI-driven review workflow that powers relevance determination, privilege identification, and entity extraction.
Rather than treating a foreign-language document as an anomaly to be handled separately, Venio’s platform identifies multilingual content, including tone, anomalies, and semantic signals, through the same AI review pipeline.
The result: a legal team reviewing a cross-border matter does not need to build a separate workflow for non-English documents. They work in one place, with one queue, under one audit trail.
Multilingual Content in a Single, Secure Review Workspace
Venio’s platform is used across countries for cross-border compliance, multilingual processing, and seamless collaboration, and that global footprint is built on a foundational principle: data never needs to leave the secure environment to be processed in any language.
Foreign-language documents reviewed within Venio maintain the same privilege protections, confidentiality standards, and chain-of-custody documentation as any other document in the matter.
There is no export, no third-party handoff, no re-import. Multilingual review happens inside the same platform where English-language review happens, with the same audit trail, the same role-based access controls, and the same defensible workflow.
Production Across Diverse Languages and Character Sets
Production is where multilingual gaps most visibly break down in fragmented environments. Venio’s document production software is built to produce content accurately across diverse languages and character sets, moving directly from review to production without data exports or handoffs.
This means legal teams can apply Bates numbering, redactions, and endorsement labels to Arabic, Chinese, Cyrillic, and Latin-script documents using the same automated production workflow.
Output formats: TIFF, PDF, native, and text are consistent regardless of source language, delivering court-ready productions that meet regulatory standards without manual exception handling for foreign-language content.
One Platform. Every Language.
How AI Transforms the Multilingual Document Review Workflow
Technology-assisted review (TAR) and continuous active learning (CAL) have transformed English-language document review over the past decade, dramatically reducing the volume of documents requiring human eyes without sacrificing recall. The promise of AI for multilingual eDiscovery is the same. The delivery has historically been inconsistent.
Venio’s approach integrates AI at the layer where it matters most: not as a translation layer applied after the fact, but as an analytical framework applied to multilingual content natively. Here is what that means across four critical capabilities:

The combined effect is substantial. For a matter where 30% of documents are in non-English languages, AI-assisted multilingual review reduces the number of documents requiring attorney-level human review by a significant margin, compressing the timeline, lowering the bilingual attorney premium, and delivering more defensible coverage of the full corpus.
Detect, Rank, and Process Foreign Languages Documents
See Multilingual Review in Action
eDiscovery Translation Strategy: When to Use Machine vs. Human
Automated translation has transformed the economics of multilingual document review. The ability to run bulk machine translation (MT) over large foreign-language datasets inside the secure review environment means legal teams can make initial responsiveness determinations without engaging human translators for every document.
But overreliance on machine translation carries real risk. Automated translation cannot reliably capture legal nuance, idiomatic language, dialectic variation, or the kind of contextual ambiguity that determines whether a document is privileged, responsive, or strategically significant. The goal is not to replace human judgment. It is to deploy human expertise where it creates the highest value.
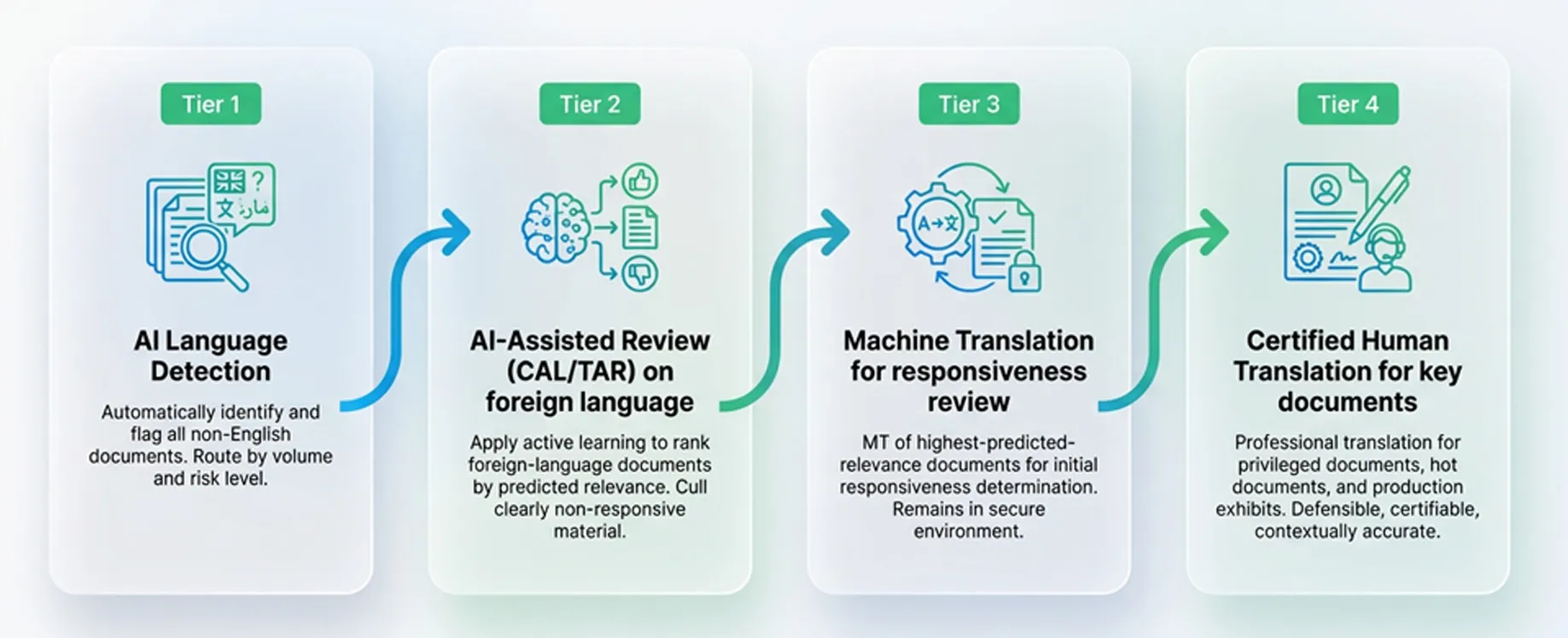
This tiered approach is where Venio’s platform architecture delivers its clearest advantage: each tier flows into the next inside the same system. AI detection, CAL ranking, and in-platform flagging for translation are not separate processes that require tool switching. They are sequential steps in a single, auditable workflow.
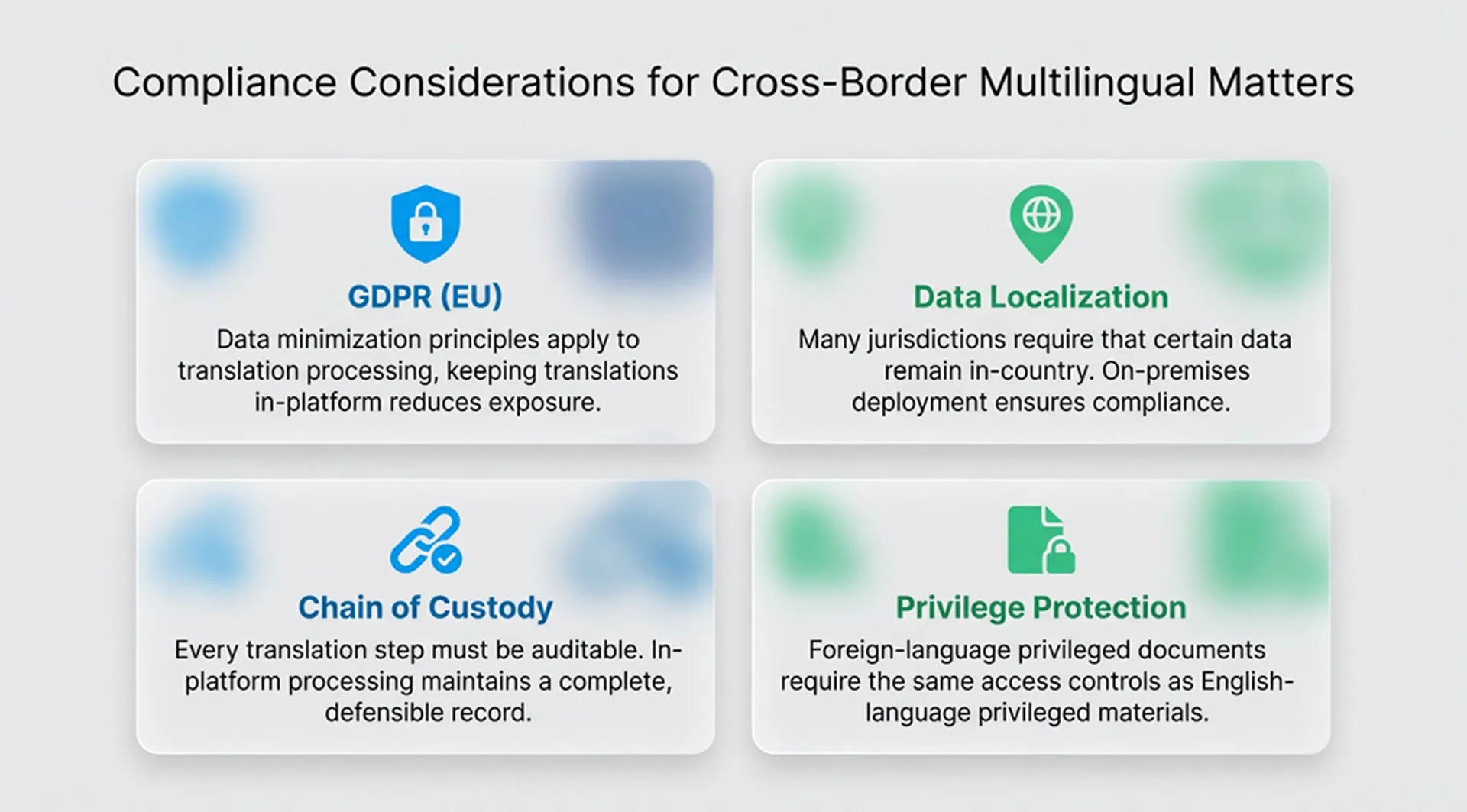
Cross-Border Compliance and Data Security in Multilingual Matters
International matters introduce data sovereignty challenges that make platform choice a compliance decision as much as an operational one. GDPR and similar privacy frameworks create real constraints on where data can be stored, processed, and transmitted; constraints that become acutely relevant when documents leave a review platform to travel through third-party translation services.
Venio’s architecture addresses this directly. Its flexible deployment model: cloud, on-premises, or hybrid, allows legal teams to choose the environment that matches their data residency requirements.
For matters in heavily regulated jurisdictions, the on-premises deployment option keeps sensitive ESI entirely within the client’s controlled infrastructure, with no exposure to external networks during multilingual processing.
The platform’s role-based access controls, encrypted export options, and secure file packaging apply equally to foreign-language documents as to any other ESI. Multilingual documentation processed in Venio is subject to the same security architecture as the rest of the matter, not a parallel workflow with a different (and weaker) chain of custody.
The Venio Advantage: One Platform, Every Language
The case for a unified multilingual eDiscovery platform is ultimately a case against complexity. Every vendor added to a multilingual workflow is another point of failure, another contract, another security review, another handoff that can introduce delay, cost, and defensibility risk.
Venio Systems was built on the premise that eDiscovery should not require an ecosystem of compensating tools. Fifteen-plus years of legal tech innovation, deployment across many countries, and a platform architecture that spans legal hold to production in a single system; these are the foundations on which Venio’s multilingual capabilities are built.
For law firms, corporate legal departments, and government agencies managing global matters, this is what eDiscovery should look like: one login, one workflow, complete coverage regardless of how many languages the data speaks.
Bring Every Language Into One Defensible Workflow
Cross-border litigation is not going to get simpler. International regulatory scrutiny will intensify. Enterprise data will continue to grow in linguistic diversity. The organizations that manage these matters most effectively will be those that stopped treating multilingual document processing as a specialty challenge and started treating it as a baseline requirement of their eDiscovery infrastructure.
The Platform Fragmentation Tax is real, measurable, and avoidable. Every dollar spent on external translation vendors, every hour lost in handoff delays, and every defensibility gap created by documents that left the secure review environment is a cost that a unified, language-aware platform eliminates at the source.
Venio Systems delivers that platform. AI-powered. Flexible in deployment. Built for multilingual documentation from the ground up. And proven across the cross-border matters where these capabilities matter most. So, contact us today to streamline cross-border discovery without compromising speed, accuracy, or defensibility.
Related Articles

The Professional's Guide to eDiscovery Production
This guide breaks down how eDiscovery works, what happens during production, and
Read Article
What Are Litigation Searches? A Complete Guide
Litigation can leave a long trail and litigation searches are how smart legal te
Read Article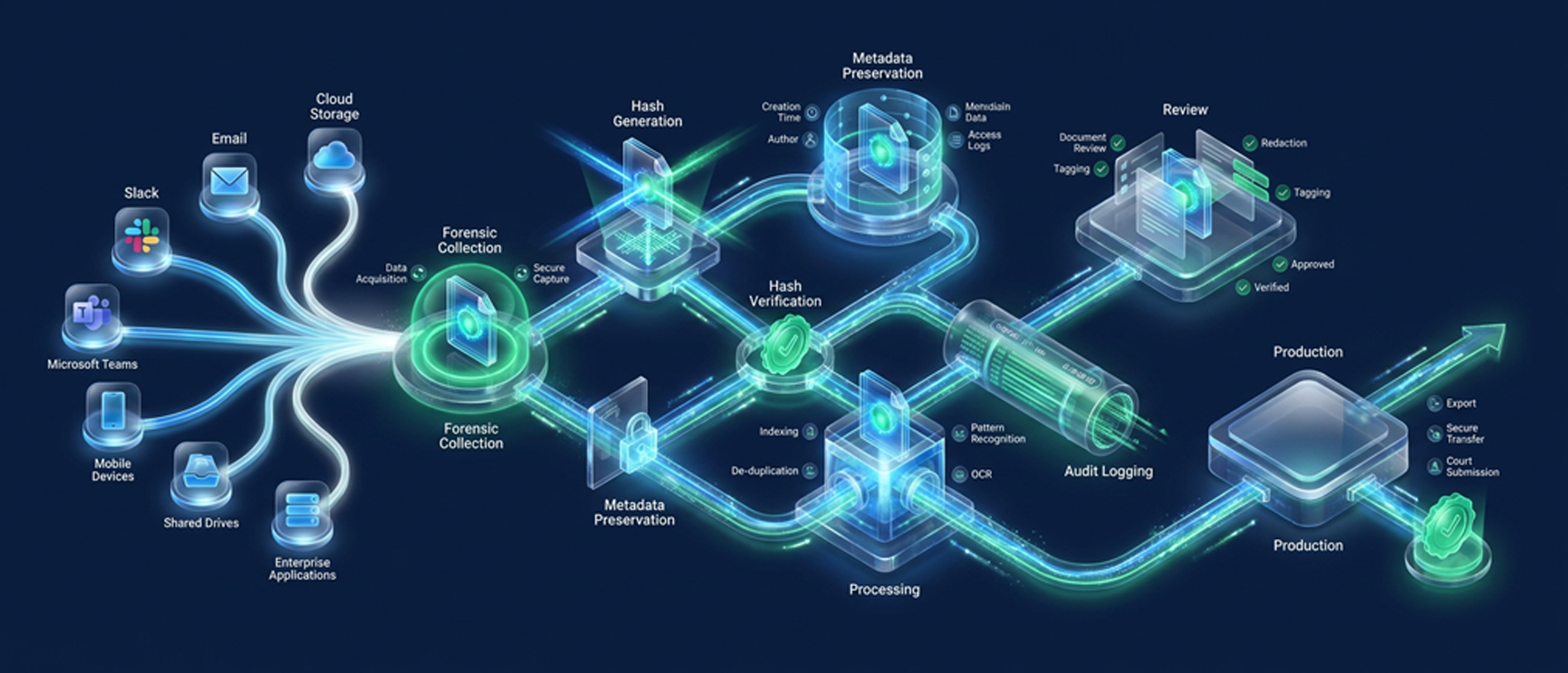
Digital Chain of Custody: How to Track Electronic Evidence
A digital chain of custody tracks electronic evidence through every system that
Read Article